Learning to Search, Searching to Learn: A Closed-Loop Framework for Large-Scale Vehicle Routing Problems
NeurIPS 2026 (submission), Under review, 2025
abstract
Large-scale Vehicle Routing Problems (VRPs) face two long-standing difficulties. On the one hand, many scalable methods rely on partitioning, local candidate restriction, or staged decision making to control computation, which weakens their modeling of global structure. On the other hand, although many methods introduce search at test time to improve the final solution, search is still typically used only as a one-shot post-processing step after model prediction. The model makes a prediction, search repairs it, and little sustained feedback is formed between the two. Improved structural states are rarely fed back to the model for subsequent inference, and high-quality search solutions are seldom turned into later training supervision.
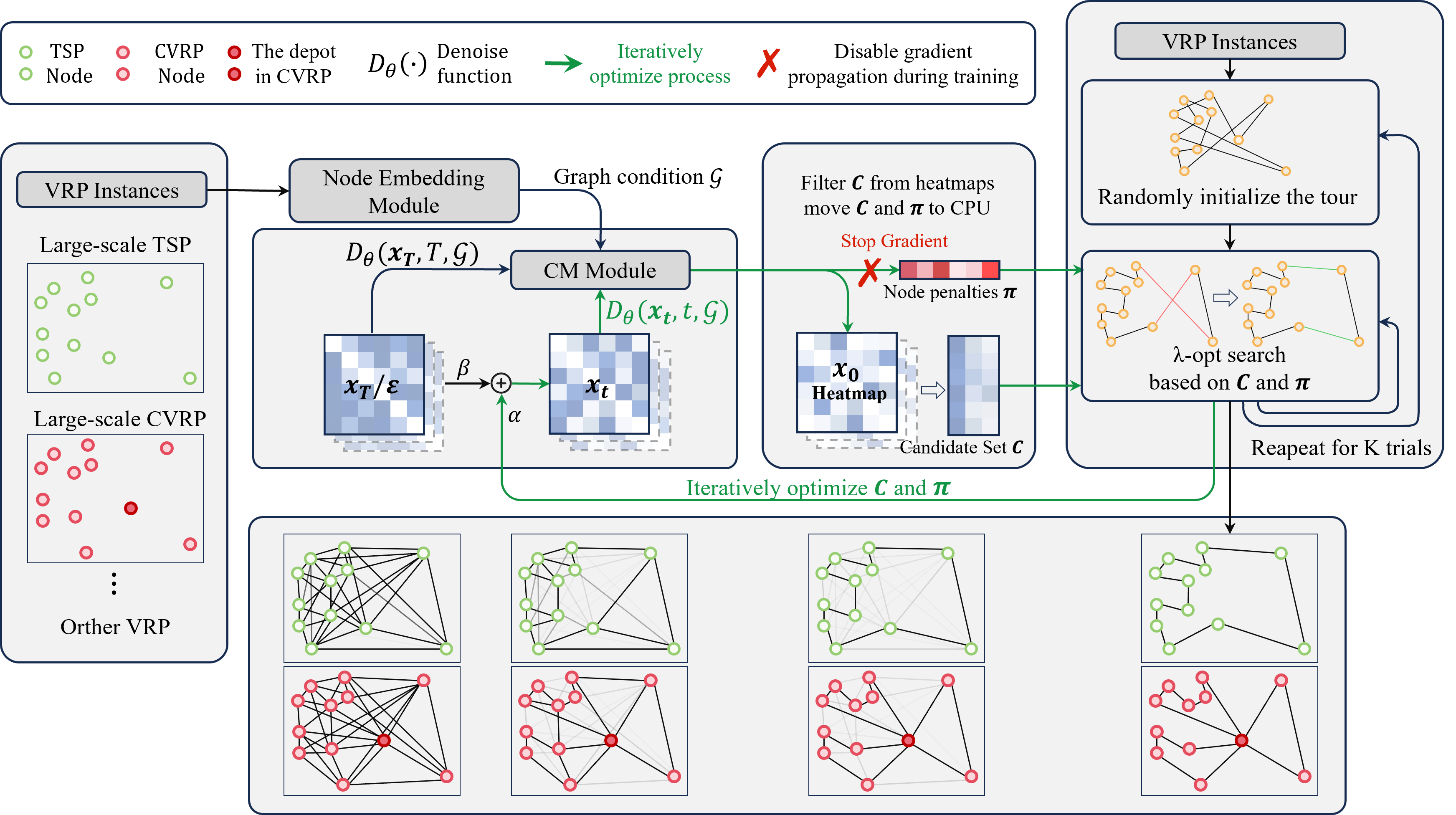
To address this issue, we propose LSL (Learning to Search, Searching to Learn), a closed-loop learning-search framework for large-scale VRPs. LSL first predicts search-friendly structural priors on a sparse candidate graph, and search then iteratively refines the current solution under the guidance of these priors. In turn, search does not leave the system after one round of refinement. At inference time, the structural states returned by search are fed back to the model for the next round of prediction, while at training time, multiple high-quality search solutions are reorganized into row-wise soft targets for model update. In this way, learning tells search where to explore, and search tells the model which structures are worth learning. Experiments show that LSL achieves strong scalability, efficiency, and solution quality across multiple large-scale VRP benchmarks.
Motivation
Existing learning-based VRP solvers scale by cutting the decision space — partitioning the graph, masking candidates, or making decisions in stages. These shortcuts help the model fit in memory but also throw away the global structure the model needs to reason over. Meanwhile, test-time search is usually bolted on at the end as a fixed post-processor, and what it discovers never flows back into the model.
Framework
LSL closes the loop between learning and search:
- Sparse structural prior. The model predicts a search-friendly prior over a sparse candidate graph, giving search a warm direction instead of starting cold.
- Guided iterative search. Local search refines the current solution under that prior, keeping the exploration budget focused.
- Structural feedback at inference. The structural state produced by search is fed back to the model for the next prediction round — not discarded.
- Soft supervision at training. Multiple high-quality search solutions are aggregated into row-wise soft targets so the model keeps learning from what search has already found.
The two directions reinforce each other: learning tells search where to explore, search tells the model which structures are worth learning.
Figure