Yongji Fu, et al.
撰写中;目标:ICRA 2026, 撰写中, 2025
摘要 · 引用
仿人面部机器人的表情需要在”对观察者而言看起来自然”与”在有限驱动能力的机械面部上可执行”
之间达到平衡。本文学习一种从目标面部信号到机器人底层执行器指令的映射,不只复现静态关键
表情,还复现了类人化的微动态,同时保持机械极限内的稳定。工作包括数据采集、重定向,以及
一个在视觉逼真度与物理可行性之间做折衷的学习控制器。
@unpublished{fu2025humanoidface,
title={Learning Realistic Expressions for Humanoid Face Robots},
author={Fu, Yongji and others},
note={Manuscript in preparation; target venue: IEEE International Conference on Robotics and Automation (ICRA) 2026},
year={2025}
}
Yongji Fu, Yong Wang, Jun Deng, et al.
NeurIPS 2026(投稿中), 审稿中, 2025
pdf · 摘要 · 引用
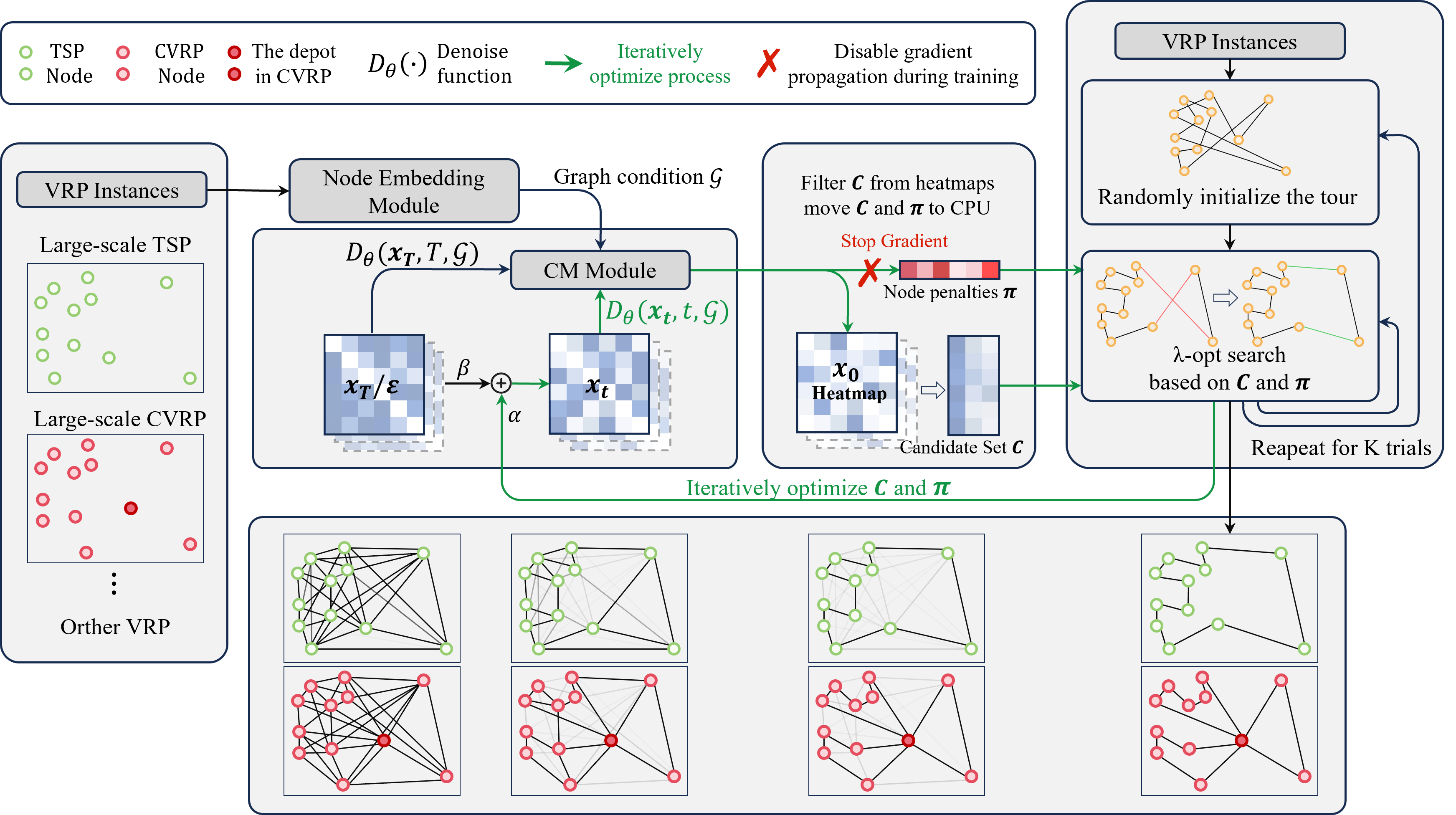
大规模车辆路径问题 (VRP) 面临两个长期难题。一方面,许多可扩展方法依赖于图划分、邻域候选限制或分阶段决策来控制计算量,
这削弱了模型对全局结构的建模能力;另一方面,虽然许多方法在测试阶段引入搜索以提升解质量,但搜索通常只作为模型预测之后
的一次性后处理——模型给出预测,搜索进行修复,两者之间缺乏持续反馈:改进后的结构状态很少被反馈回模型指导后续推理,
而高质量的搜索解也几乎不会进入后续的训练监督。
为解决这一问题,我们提出 LSL(Learning to Search, Searching to Learn),
一个面向大规模 VRP 的学习—搜索闭环框架。LSL 首先在稀疏候选图上预测搜索友好的结构先验,随后搜索在这些先验的引导下
迭代精化当前解。更关键的是,搜索并不在一轮精化后就退出系统:推理阶段,搜索返回的结构状态被反馈给模型,用于下一轮预测;
训练阶段,多条高质量搜索解被组织成行级软目标,用于模型更新。由此形成”学习告诉搜索去哪里探索,搜索告诉模型哪些
结构值得学习”的闭环。实验表明,LSL 在多个大规模 VRP 基准上同时取得良好的可扩展性、效率和解质量。
@article{fu2025learning,
title={Learning to Search, Searching to Learn: A Closed-Loop Framework for Large-Scale Vehicle Routing Problems},
author={Fu, Yongji and Wang, Yong and Deng, Jun and others},
journal={Submitted to NeurIPS 2026},
year={2025}
}
Guanqun Cao, Yongji Fu, Yi Zhou, Gaojie Jin, Zhenyu Lu, Shan Luo
IEEE Transactions on Robot Learning (TRL)(投稿中), 审稿中, 2025
pdf · 摘要 · 引用
触觉传感能通过接触直接获取物体的物理属性,然而大多数现有方法仅采用预定义属性标签来描述触觉数据,
语义灵活性受限。将触觉信号与自然语言对齐,可以得到更丰富的、概念级别的表示。
本文提出一种基于 Transformer 的触觉—语言框架,借助 Steering Vectors 将共享嵌入空间
组织为可操控的概念空间:这些向量把触觉属性编码为语义方向,使模型在有限监督下仍能对语义实施
显式控制。同一潜空间支持两个互补任务:给定描述期望触觉属性的自然语言查询时,机器人可在其触觉
经验中检索最相关的材料;而当机器人实际接触物体表面后,可生成对该表面触觉属性的自然语言描述。
实验结果表明,该框架能够从自由形式的自然语言中有效检索触觉表示,并生成具有感知依据的触觉描述,
从而更好地支持人—机器人交互。
@article{cao2025touchsteer,
title={TouchSteer: Grounding Natural Language in Tactile Perception via Steering Vectors},
author={Cao, Guanqun and Fu, Yongji and Zhou, Yi and Jin, Gaojie and Lu, Zhenyu and Luo, Shan},
journal={Submitted to IEEE Transactions on Robot Learning},
year={2025}
}
Yongji Fu, et al.
撰写中;目标:ICRA 2026, 撰写中, 2025
摘要 · 引用
需要丰富接触的操作任务,要求世界模型不仅能预测动作之后场景看起来是什么样,还要预测指尖
感受到什么。本文训练一个视觉—触觉联合的潜空间世界模型,将视觉与触觉信号联合编码到
共享潜空间,并在该空间中推演未来状态。该模型可用于规划与策略学习,适合打滑、粘连、力突变
等视觉看不到但触觉能捕捉到的任务。
我们在仅凭视觉存在歧义的操作任务上进行评估,结果显示在潜空间动力学中引入触觉通道可同时
改善状态预测精度与下游任务成功率。
@unpublished{fu2025visuotactile,
title={Visuo-Tactile Latent World Models},
author={Fu, Yongji and others},
note={Manuscript in preparation; target venue: IEEE International Conference on Robotics and Automation (ICRA) 2026},
year={2025}
}