Learning to Search, Searching to Learn:面向大规模车辆路径问题的闭环框架
NeurIPS 2026(投稿中), 审稿中, 2025
摘要
大规模车辆路径问题 (VRP) 面临两个长期难题。一方面,许多可扩展方法依赖于图划分、邻域候选限制或分阶段决策来控制计算量, 这削弱了模型对全局结构的建模能力;另一方面,虽然许多方法在测试阶段引入搜索以提升解质量,但搜索通常只作为模型预测之后 的一次性后处理——模型给出预测,搜索进行修复,两者之间缺乏持续反馈:改进后的结构状态很少被反馈回模型指导后续推理, 而高质量的搜索解也几乎不会进入后续的训练监督。
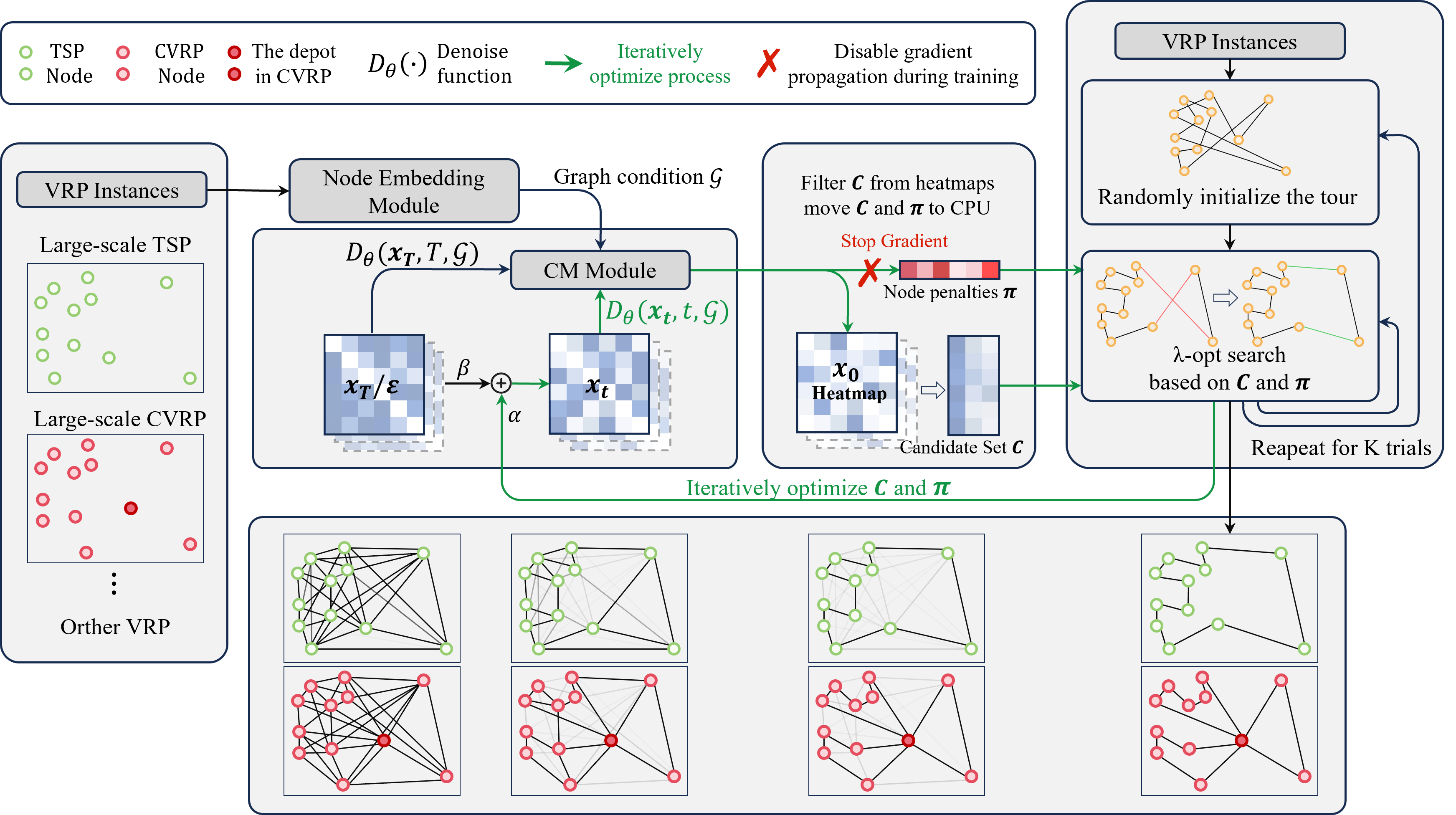
为解决这一问题,我们提出 LSL(Learning to Search, Searching to Learn), 一个面向大规模 VRP 的学习—搜索闭环框架。LSL 首先在稀疏候选图上预测搜索友好的结构先验,随后搜索在这些先验的引导下 迭代精化当前解。更关键的是,搜索并不在一轮精化后就退出系统:推理阶段,搜索返回的结构状态被反馈给模型,用于下一轮预测; 训练阶段,多条高质量搜索解被组织成行级软目标,用于模型更新。由此形成”学习告诉搜索去哪里探索,搜索告诉模型哪些 结构值得学习”的闭环。实验表明,LSL 在多个大规模 VRP 基准上同时取得良好的可扩展性、效率和解质量。
Motivation
Existing learning-based VRP solvers scale by cutting the decision space — partitioning the graph, masking candidates, or making decisions in stages. These shortcuts help the model fit in memory but also throw away the global structure the model needs to reason over. Meanwhile, test-time search is usually bolted on at the end as a fixed post-processor, and what it discovers never flows back into the model.
Framework
LSL closes the loop between learning and search:
- Sparse structural prior. The model predicts a search-friendly prior over a sparse candidate graph, giving search a warm direction instead of starting cold.
- Guided iterative search. Local search refines the current solution under that prior, keeping the exploration budget focused.
- Structural feedback at inference. The structural state produced by search is fed back to the model for the next prediction round — not discarded.
- Soft supervision at training. Multiple high-quality search solutions are aggregated into row-wise soft targets so the model keeps learning from what search has already found.
The two directions reinforce each other: learning tells search where to explore, search tells the model which structures are worth learning.
Figure